
The new, interactive game recommending model isn’t going to rely on whether a game is popular or not at the moment.
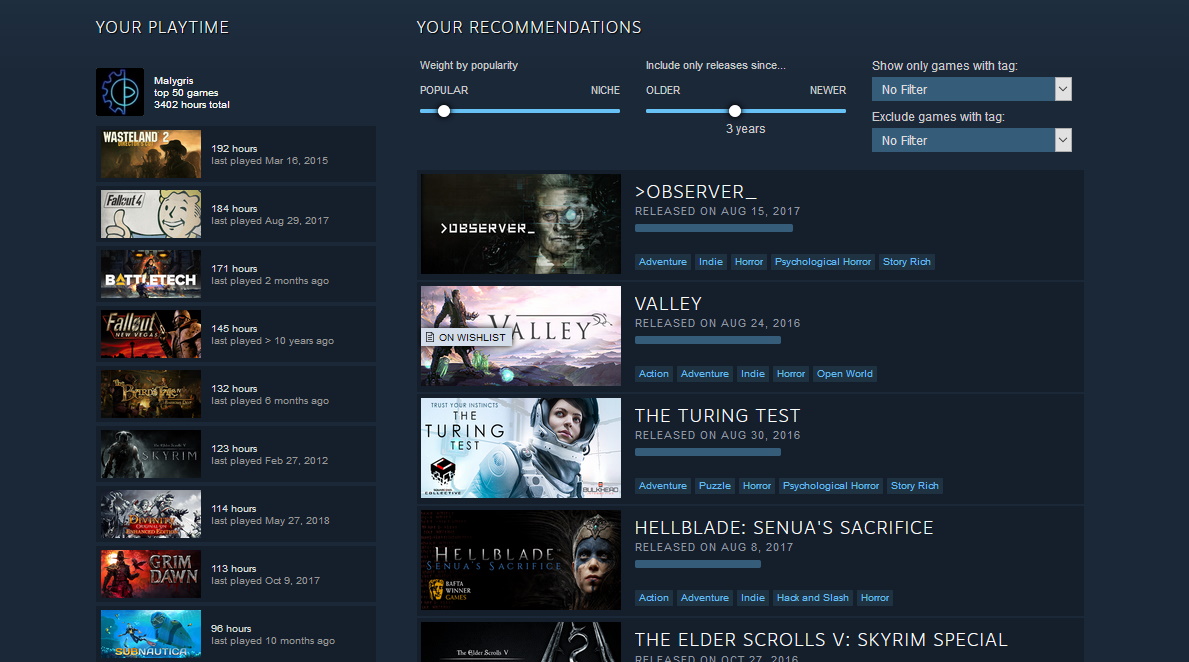
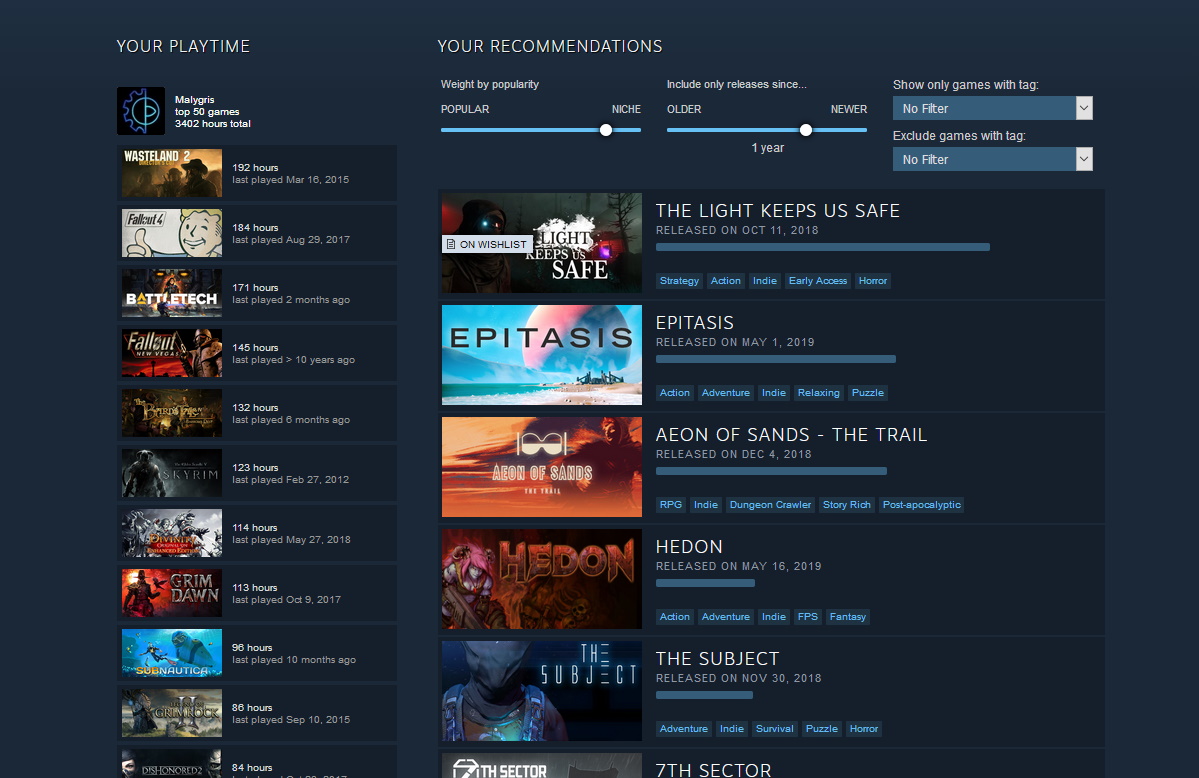
Recommender is one of the new Steam experimental functions with a „neural network model,” which doesn’t rely on tags, but the time spent in games we played instead, and it refreshes game recommendations in free time if we fine-tune the recommended games’ age (for example, three years old or newer) or popularity.
„We train the model based on data from many millions of Steam users and many billions of play sessions, giving us robust results that capture the nuances of different play patterns and covers our catalogue. The model is parameterized so that we can restrict output to games released within a specified time-window, and can be adjusted to prefer games [with] a higher or lower underlying popularity.
These parameters are exposed to the user, allowing you to select whether to see only recent releases in the results or go all the way back to include games released a decade ago. Similarly, you can choose whether to see mainstream hits or deep cuts from the catalogue. Regardless of the settings of the sliders, the results will always be personalized and relevant to the individual user. In fact, the only information about a game that gets explicitly fed into the process is the release date, enabling us to do time-windowing for the release-date slider.
We designed the recommender to be driven by what players do, not by extrinsic elements like tags or reviews. The best way for a developer to optimize for this model is to make a game that people enjoy playing. While it’s important to supply users with useful information about your game on its store page, you shouldn’t agonize about whether tags or other metadata will affect how a recommendations model sees your game.
We view this new Interactive Recommender as one discovery element among many, and look forward to introducing more ways to connect customers with interesting content and developers,” Valve explained in a blog post.
Currently, this model is different from the ordinary, tag-based algorithm system, but via early adopters, the machine learning model can be trained before it’s likely getting a worldwide or complete rollout.
Source: PCGamer







![[TGA 2025] LEGO Batman Is Back, and This Time the Legend Needs Allies: Legacy of the Dark Knight [VIDEO]](https://thegeek.games/wp-content/uploads/2025/12/theGeek-LEGO-Batman-Legacy-of-the-Dark-Knight-302x180.jpg)






Leave a Reply